









【中国发明,中国发明授权】一种采用十字链表的星敏感器筛选导航星的方法
无权-未缴年费 中国
- 申请号:
- CN201210343943.5
- 授权公告日/公开日:
- 2015.07.22
- 专利有效期:
- 2012.09.17-2032.09.17
- 技术分类:
- G01:测量;测试
- 转化方式:
- 转让
- 价值度指数:
-
- 52.0分
- 价格:
- 面议
发布人
朱锡芳
联系人朱锡芳
-

- 13011000141




- 专利信息&法律状态
- 专利自评
- 专利技术文档
- 价值度指数
- 发明人阵容
 著录项
著录项
- 申请号
- CN201210343943.5
- 申请日
- 20120917
- 公开/公告号
- CN102865865A
- 公开/公告日
- 20130109
- 申请/专利权人
- [常州工学院, 苏州大学]
- 发明/设计人
- [吴峰, 沈为民, 朱锡芳]
- 主分类号
- G01C21/02
- IPC分类号
- C12N 9/0008(2013.01) C12N 9/16
- CPC分类号
- C12N 9/0008(2013.01) C12N 9/16(2013.01)
- 分案申请地址
- 国省代码
- 江苏(32)
- 颁证日
- G06T1/00
- 代理人
- [汤志和]
摘要
本发明涉及一种采用十字链表的星敏感器筛选导航星的方法,包括:一、根据星敏感器的极限星等,对全天球的原始星表作星过滤处理,并确定星数阈值Nth;二、所述星敏感器在当前天区视场内的剩余星的数量设为N,若N≤Nth,则所述剩余星都选为导航星,执行步骤三;若N>Nth,则通过多尺度像面分割筛选所述当前天区视场内的导航星,三、所述当前天区视场的导航星筛选结束后,所述星敏感器转到下一方位重复步骤(二)筛选导航星,直至遍历全天球;本发明中的采用多尺度像面分割筛选的方法能适应不同天区的星数变化删除星分布高密度天区的冗余星,保留低密度天区的所有星,并且筛选的导航星分布均匀。
法律状态
| 法律状态公告日 | 20181207 |
| 法律状态 | 专利权的终止 |
| 法律状态信息 | 未缴年费专利权终止 IPC(主分类):G01C 21/02 申请日:20120917 授权公告日:20150722 终止日期:20170917 |
| 法律状态公告日 | 20150722 |
| 法律状态 | 授权 |
| 法律状态信息 | 授权 |
| 法律状态公告日 | 20130220 |
| 法律状态 | 实质审查的生效 |
| 法律状态信息 | 实质审查的生效 IPC(主分类):G01C 21/02 申请日:20120917 |
| 法律状态公告日 | 20130109 |
| 法律状态 | 公开 |
| 法律状态信息 | 公开 |
权利要求
权利要求数量(4)
独立权利要求数量(1)
1.一种采用十字链表的星敏感器筛选导航星的方法,包括:
步骤一、根据星敏感器的极限星等,对全天球的原始星表作星过滤处 理,即删除双星、变星和星等高于极限星等的恒星;并根据星图识别算法 确定星数阈值N th;
步骤二、所述星敏感器在当前天区视场内的剩余星的数量设为N,若N ≤N th,则所述剩余星都选为导航星,执行步骤三;
若N>N th,则通过多尺度像面分割筛选所述当前天区视场内的导航星, 其步骤如下:
步骤(1)将所述剩余星成像到像面,把该像面分割为行数为p、列数为 q的正交网格;所述正交网格中的每个网格为一个小区;
步骤(2)依次遍历各小区,检查其中剩余星的数量,其中,若一小区剩 余星的数量有多颗,则保留其中最亮的一颗星,删除其余星;同时判断此 时剩余星的数量,若N≤N th,则设当前剩余星为导航星,遍历结束,执行步 骤三;若N>N th,则继续遍历;若遍历所有小区后,N仍大于N th,则把小区 当作像元,若小区内有星,则该像元的灰度值为非0,若小区内无星,则该 像元的灰度值为0,遍历后的具有剩余星的相邻小区划分为连通域,将正交 网格数据存储为十字链表,采用区域增长算法计算出各连通域的质心坐标;
步骤(3)选取小区数最多的连通域,设在该连通域中离该连通域的质 心坐标最近的一颗星为冗余星;若该连通域中离质心坐标最近的星有多颗, 则其中最暗的一颗星为冗余星;若小区数最多的连通域有多个,则选择这 些连通域中最暗的一颗星为冗余星;删除所述冗余星;判断此时剩余星的 数量,若N≤N th,则设当前剩余星为导航星,执行步骤三;若N>N th,则重 复该步骤(3);
步骤(4)若不再有连通域后;N仍大于N th,则所述p和q的取值都减 1,重复步骤(1)至(4);直到N≤N th;
步骤三、所述当前天区视场的导航星筛选结束后,所述星敏感器转到 下一方位重复步骤二筛选导航星,直至遍历全天球。
2.根据权利要求1所述的星敏感器筛选导航星的方法,其特征在于: 所述步骤(2)中所述若一小区剩余星的数量有多颗,则保留其中最亮的一 颗星,删除其余星的方法包括:
在所述正交网格中预先定义三个二维数组Marray、Idarray和 MAGarray;若所述正交网格中第m行、n列的小区有至少有一颗星,则 Marray[m][n]=1,否则为零;若所述小区内有多颗星,则用IDarray[m][n] 和MAGarray[m][n]分别记录最亮的一颗星的星号和星等,并删除其余星。
3.根据权利要求2所述的星敏感器筛选导航星的方法,其特征在于: 所述步骤(2)中所述将正交网格数据存储为十字链表,采用区域增长算法 计算出各连通域的质心坐标的方法包括:
步骤A、所述若小区内有星,则该像元的灰度值为非0,若小区内无星, 则该像元的灰度值为0,即把所述二维数组Marray转换成一星图,所述各 连通域转换成各星象,并将所述星图转换为十字链表;提取灰度值为非0 的星图像元的坐标(x,y)和灰度值f(x,y),并把所述星像像元的坐标(x,y) 和灰度值f(x,y)存储到十字链表的节点中;
步骤B、定义初始值为0的三个变量ACC1、ACC2、ACC3作为三个累加 器;
步骤C、在星图中,一个星像占据一个连通的区域,将该连通的区域称 为一个星像区域;以区域增长算法连通一星像区域,即以所述十字链表中 的第一个节点为启始种子,依次提取代表邻域节点的像元的坐标(x,y)和灰 度值f(x,y),同时将所述的三个累加器分别增加xf(x,y)、yf(x,y)、f(x,y), 并将提取过所述坐标(x,y)和灰度值f(x,y)的节点从所述十字链表中删除; 重复该步骤三,直至所述星像区域已经连通;
步骤D、使用所述三个累加器计算该星像的质心坐标(x c,y c),即 质心坐标(x c,y c)为:
步骤E、将所述的三个累加器置0,重复上述步骤C至D,直至所述十 字链表为空,即所有星像的质心坐标计算完毕。
4.根据权利要求1所述的星敏感器筛选导航星的方法,其特征在于: 所述p和q的初始值的比值与所述像面的行、列尺寸比相同。
1.一种采用十字链表的星敏感器筛选导航星的方法,包括:
步骤一、根据星敏感器的极限星等,对全天球的原始星表作星过滤处理,即删除双星、变星和星等高于极限星等的恒星;并根据星图识别算法确定星数阈值Nth;
步骤二、所述星敏感器在当前天区视场内的剩余星的数量设为N,若N≤Nth,则所述剩余星都选为导航星,执行步骤三;
若N>Nth,则通过多尺度像面分割筛选所述当前天区视场内的导航星,其步骤如下:
步骤(1)将所述剩余星成像到像面,把该像面分割为行数为p、列数为q的正交网格;所述正交网格中的每个网格为一个小区;
步骤(2)依次遍历各小区,检查其中剩余星的数量,其中,若一小区剩余星的数量有多颗,则保留其中最亮的一颗星,删除其余星;同时判断此时剩余星的数量,若N≤Nth,则设当前剩余星为导航星,遍历结束,执行步骤三;若N>Nth,则继续遍历;若遍历所有小区后,N仍大于Nth,则把小区当作像元,若小区内有星,则该像元的灰度值为非0,若小区内无星,则该像元的灰度值为0,遍历后的具有剩余星的相邻小区划分为连通域,将正交网格数据存储为十字链表,采用区域增长算法计算出各连通域的质心坐标;
步骤(3)选取小区数最多的连通域,设在该连通域中离该连通域的质心坐标最近的一颗星为冗余星;若该连通域中离质心坐标最近的星有多颗,则其中最暗的一颗星为冗余星;若小区数最多的连通域有多个,则选择这些连通域中最暗的一颗星为冗余星;删除所述冗余星;判断此时剩余星的数量,若N≤Nth,则设当前剩余星为导航星,执行步骤三;若N>Nth,则重复该步骤(3);
步骤(4)若不再有连通域后;N仍大于Nth,则所述p和q的取值都减1,重复步骤(1)至(4);直到N≤Nth;
步骤三、所述当前天区视场的导航星筛选结束后,所述星敏感器转到下一方位重复步骤二筛选导航星,直至遍历全天球。
2.根据权利要求1所述的星敏感器筛选导航星的方法,其特征在于:所述步骤(2)中所述若一小区剩余星的数量有多颗,则保留其中最亮的一颗星,删除其余星的方法包括:
在所述正交网格中预先定义三个二维数组Marray、Idarray和MAGarray;若所述正交网格中第m行、n列的小区有至少有一颗星,则Marray[m][n]=1,否则为零;若所述小区内有多颗星,则用IDarray[m][n]和MAGarray[m][n]分别记录最亮的一颗星的星号和星等,并删除其余星。
3.根据权利要求2所述的星敏感器筛选导航星的方法,其特征在于:所述步骤(2)中所述将正交网格数据存储为十字链表,采用区域增长算法计算出各连通域的质心坐标的方法包括:
步骤A、所述若小区内有星,则该像元的灰度值为非0,若小区内无星,则该像元的灰度值为0,即把所述二维数组Marray转换成一星图,所述各连通域转换成各星象,并将所述星图转换为十字链表;提取灰度值为非0的星图像元的坐标(x,y)和灰度值f(x,y),并把所述星像像元的坐标(x,y)和灰度值f(x,y)存储到十字链表的节点中;
步骤B、定义初始值为0的三个变量ACC1、ACC2、ACC3作为三个累加器;
步骤C、在星图中,一个星像占据一个连通的区域,将该连通的区域称为一个星像区域;以区域增长算法连通一星像区域,即以所述十字链表中的第一个节点为启始种子,依次提取代表邻域节点的像元的坐标(x,y)和灰度值f(x,y),同时将所述的三个累加器分别增加xf(x,y)、yf(x,y)、f(x,y),并将提取过所述坐标(x,y)和灰度值f(x,y)的节点从所述十字链表中删除;重复该步骤三,直至所述星像区域已经连通;
步骤D、使用所述三个累加器计算该星像的质心坐标(xc,yc),即质心坐标(xc,yc)为: x c = ACC 1 ACC 3 , ]]> y c = ACC 2 ACC 3 ; ]]>
步骤E、将所述的三个累加器置0,重复上述步骤C至D,直至所述十字链表为空,即所有星像的质心坐标计算完毕。
4.根据权利要求1所述的星敏感器筛选导航星的方法,其特征在于:所述p和q的初始值的比值与所述像面的行、列尺寸比相同。
说明书
技术领域
本发明属于天文导航技术领域,涉及一种采用十字链表的星敏感器筛选导航星的方法。
背景技术
星敏感器通过星图识别,比较观测星星组和导航星星组的特征,识别观测星,确定它们在本体坐标系和惯性坐标系中的坐标,从而测量出卫星姿态,是现代航天领域中一种精度最高的卫星姿态测量仪器。星图识别是星敏感器的核心技术,建立导航星星库是识别星图的重要前提,合理选择导航星对于降低导航星星组特征相似性,提高星图识别速率和星图识别成功率,增强星敏感器抗伪星干扰能力,提高姿态测量精度有重要意义。
导航星在全天球上分布均匀时,导航星星组特征冗余性小,星图识别稳定性高,通常以导航星分布均匀性评价优选(筛选)算法,目前的导航星优选(筛选)算法大致可以分为两大类。
第一类算法以导航星在全天球的均匀分布为出发点。1998年林涛等提出的正交网格方法将单位天球投影到平面上,正交分割该投影平面,将全天球分成很多互不交叉的等面积天区,在每个天区中选取一颗恒星为导航星。由于天区长宽比随着纬度变化,导航星密度并不均匀。2004年Samaan,Malak A等提出的球面分块法(The Spherical Patches method)、固定斜度螺旋线法(The Fixed-Slope Spiral method)和带电粒子法(The ChargedParticles method)等算法均分天球,每个天区长宽比与所处位置的关系不大,得到的导航星分布也更均匀。2004年发表在ELECTRONICS LETTERS第40卷第2期上的基于玻尔兹曼熵的导航星优选算法,从选定的两颗导航星出发,逐个选取其他导航星,使所有已选导航星的玻尔兹曼熵最小,该算法可以有效删除冗余星,获得均匀的全天球导航星分布。此类算法较少考虑星敏感器的视场和各个天区视场内导航星的数目,虽然可以实现导航星均匀分布,但当视场很大时,每次可观测到的导航星仍有冗余。
第二类算法从导航星在局部天球上的均匀分布出发,实现在全天球上的均匀分布。2000年李立宏等提出星等加权方法,按照星等给每颗恒星赋予不同的权值,低星等的恒星有高权值,高星等的恒星有低权值,根据权值选取导航星,算法优于正交网格方法,但该算法较少考虑恒星位置,导航星分布均匀性有待提高。2002年Texas A&M大学Hye-Young Kim等提出了自组织导航星选取算法,在满足任意轴指向的视场内达到一定导航星数的前提下,根据恒星的位置关系,逐个挑选导航星,导航星分布在局部和全天球上都较均匀。2004年郑胜等提出的回归选取算法根据视场内可观测到的恒星数,基于支持向量机的方法,生成动态星等阈值,依据该阈值筛选不同天区视场内的观测星获得导航星,该方法能得到比较均匀的导航星分布,但对于有固定极限星等的星敏感器,回归选取算法得到的导航星分布仍不够均匀。
发明内容
本发明要解决的技术问题是提供一种采用十字链表计算质心,并适用于星敏感器以均匀筛选出导航星的方法。
本发明的基本思想是,由于星敏感器的视场内的天区只占据全天球的很小一部分,所以该视场内的天区可看成是平面区域,如果任意视场内的导航星成像的像面均匀分布,那么导航星在全天球上也近似均匀分布。这样,可以根据像面上的星像密度筛选导航星,把导航星在全天球上的分布问题转换为其星像在像面上的分布问题。
在所述基本思想下,本发明提供了一种采用十字链表的星敏感器筛选导航星的方法,包括:
步骤一、根据星敏感器的极限星等,对全天球的原始星表作星过滤处理,即删除双星、变星和星等高于极限星等的恒星;并根据星图识别算法确定星数阈值Nth;
步骤二、所述星敏感器在当前天区视场内的剩余星的数量设为N,若N≤Nth,则所述剩余星都选为导航星,执行步骤三;
若N>Nth,则通过多尺度像面分割筛选所述当前天区视场内的导航星,其步骤如下:
步骤(1)将所述剩余星成像到像面,把该像面分割为行数为p、列数为q的正交网格;所述正交网格中的每个网格为一个小区;
步骤(2)依次遍历各小区,检查其中剩余星的数量,其中,若一小区剩余星的数量有多颗,则保留其中最亮的一颗星,删除其余星;同时判断此时剩余星的数量,若N≤Nth,则设当前剩余星为导航星,遍历结束,执行步骤三;若N>Nth,则继续遍历;若遍历所有小区后,N仍大于Nth,则把小区当作像元,若小区内有星,则该像元的灰度值为非0,若小区内无星,则该像元的灰度值为0,遍历后的具有剩余星的相邻小区划分为连通域,将正交网格数据存储为十字链表,采用区域增长算法计算出各连通域的质心坐标;
步骤(3)选取小区数最多的连通域,设在该连通域中离该连通域的质心坐标最近的一颗星为冗余星;若该连通域中离质心坐标最近的星有多颗,则其中最暗的一颗星为冗余星;若小区数最多的连通域有多个,则选择这些连通域中最暗的一颗星为冗余星;删除所述冗余星;判断此时剩余星的数量,若N≤Nth,则设当前剩余星为导航星,执行步骤三;若N>Nth,则重复该步骤(3);
步骤(4)若不再有连通域后;N仍大于Nth,则所述p和q的取值都减1,重复步骤(1)至(4);直到N≤Nth;
步骤三、所述当前天区视场的导航星筛选结束后,所述星敏感器转到下一方位重复步骤二筛选导航星,直至遍历全天球。
进一步,所述步骤(2)中所述若一小区剩余星的数量有多颗,则保留其中最亮的一颗星,删除其余星的方法包括:
在所述正交网格中预先定义三个二维数组Marray、Idarray和MAGarray;若所述正交网格中第m行、n列的小区有至少有一颗星,则Marray[m][n]=1,否则为零;若所述小区内有多颗星,则用IDarray[m][n]和MAGarray[m[n]分别记录最亮的一颗星的星号和星等,并删除其余星。
进一步,为了快速的提取连通域的质心坐标,所述步骤(2)中所述将正交网格数据存储为十字链表,采用区域增长算法计算出各连通域的质心坐标的方法。该方法的基本思想是经过灰度阈值处理后的星图,星像只占少部分区域,大部分区域灰度值为0。以十字链表稀疏矩阵结构记录星图,可剔除无关信息,避免重复判断非星像像元。通过处理十字链表,即可完成提取星像。区域增长算法从启始种子开始连通星像区域,减少了判断非星像像元的次数。星图以十字链表存储时,十字链表的每个节点都代表星像像元。而以区域增长算法处理十字链表星图,不必再判断当前像元是否为星像像元。这样,可以避免重复扫描星图。如果十字链表中的星像像元已经连通,当提取一个连通区域后,该区域像元已全部从链表中删除。提取出的像元数据直接用于计算星像质心。
按照区域增长算法的基本原理,在一个星像区域的增长过程中遇到的每一个灰度大于阈值的像元都是种子,它们将执行相同的任务,检查邻域是否有新的种子,直到在新种子邻域中找不到未知的种子,此时一个星像区域已经连通。
在该基本思想下,所述步骤(2)中所述将正交网格数据存储为十字链表,采用区域增长算法计算出各连通域的质心坐标的方法包括:
步骤A、所述若小区内有星,则该像元的灰度值为非0,若小区内无星,则该像元的灰度值为0,即把所述二维数组Marray转换成一星图,所述各连通域转换成各星象,并将所述星图转换为十字链表;提取灰度值为非0的星图像元的坐标(x,y)和灰度值f(x,y),并把所述星像像元的坐标(x,y)和灰度值f(x,y)存储到十字链表的节点中;
步骤B、定义初始值为0的三个变量ACC1、ACC2、ACC3作为三个累加器;
步骤C、在星图中,一个星像占据一个连通的区域,将该连通的区域称为一个星像区域;以区域增长算法连通一星像区域,即以所述十字链表中的第一个节点为启始种子,依次提取代表邻域节点的像元的坐标(x,y)和灰度值f(x,y),同时将所述的三个累加器分别增加xf(x,y)、yf(x,y)、f(x,y),并将提取过所述坐标(x,y)和灰度值f(x,y)的节点从所述十字链表中删除;重复该步骤三,直至所述星像区域已经连通;
步骤D、使用所述三个累加器计算该星像的质心坐标(xc,yc),即
质心坐标(xc,yc)为: x c = ACC 1 ACC 3 , ]]> y c = ACC 2 ACC 3 ; ]]>
步骤E、将所述的三个累加器置0,重复上述步骤C至D,直至所述十字链表为空,即所有星像的质心坐标计算完毕。
进一步,为了更好的对像面进行分割;所述p和q的初始值的比值与所述像面的行、列尺寸比相同。
与现有技术相比,本发明具有如下优点:(1)本发明中的采用多尺度像面分割筛选的方法能适应不同天区的星数变化删除星分布高密度天区的冗余星,保留低密度天区的所有星,并且筛选的导航星分布均匀;(2)本发明把小区当作像元,小区内有星则该像元的灰度值为非0,小区内无星则该像元的灰度值为0,遍历后的具有剩余星的相邻小区划分为连通域,将正交网格数据存储为十字链表,采用区域增长算法计算出各连通域的质心坐标,并且通过该质心坐标能有效的删除高密度区的冗余星,使剩余星的分布趋向于均匀,即最后获得均匀导航星;(3)当连通一个星像后,即可直接出计算星像质心,提取星像速率快;(4)将正交网格数据存储为十字链表,采用区域增长算法计算出各连通域的质心坐标的方法只需一次星图遍历,避免重复判断星像像元;(5)通过区域增长算法能够快速的查找并判断星像区域,并实现星像和星像的分离;(6)通过星敏感器完成全天球的导航星筛选,并且筛选的全天球的导航星分布也同样均匀;(7)所述p和q的初始值的比值与所述像面的行、列尺寸比相同使小区的分割更加合理,便于p和q的递减以完成多尺度像面分割。
附图说明
为了使本发明的内容更容易被清楚的理解,下面根据的具体实施例并结合附图,对本发明作进一步详细的说明,其中
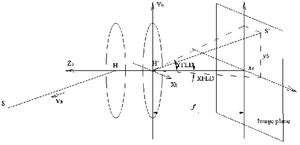
图1是本发明建立在光学系统上的本体坐标系示意图;
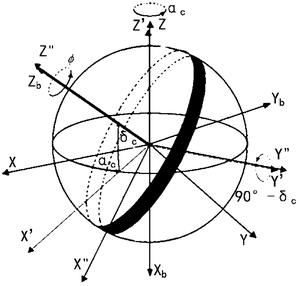
图2是惯性坐标系与本体坐标系的旋转关系示意图;
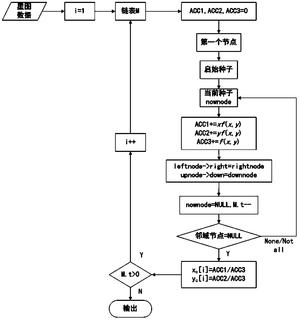
图3是本发明的计算连通域的质心坐标的方法的流程图;
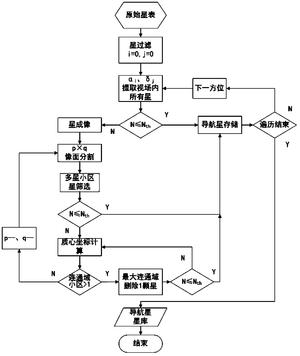
图4是本发明的星敏感器筛选导航星的方法的流程图;
图5是举例给出的原始星图;
图6是按照5×5分割像面后当前视场内恒星的分布图;
图7是删除各小区暗星后当前视场内剩余星的分布图;
图8是删除距离最大连通域质心最近处星后当前视场内剩余星的分布图;
图9是删除2个最大连通域中较暗星后当前视场内剩余星的分布图;
图10是筛选当前视场内恒星后导航星的分布图;
图11按照8×8分割像面后当前视场内恒星的分布图;
图12是删除各小区暗星后当前视场内剩余星的分布图;
图13是删除距离连通域质心最近处星后当前视场内剩余星的分布图;
图14是按照7×7分割像面后当前视场内剩余星的分布图;
图15是按照6×6分割像面后当前视场内剩余星的分布图;
图16是按照5×5分割像面后当前视场内剩余星的分布图;
图17是按照5×5分割像面处理后当前视场内导航星的分布图;
图18按照15×15分割像面后当前视场内恒星的分布图;
图19删除最大连通域中较暗星后当前视场内剩余星的分布图;
图20按照14×14分割像面后当前视场内剩余恒星的分布图;
图21按照14×14分割像面处理后当前视场内剩余恒星的分布图;
图22按照13×13分割像面后当前视场内剩余恒星的分布图;
图23按照13×13分割像面处理后当前视场内剩余恒星的分布图;
图24按照12×12分割像面处理后当前视场内剩余恒星的分布图;
图25按照11×11分割像面处理后当前视场内剩余恒星的分布图;
图26按照10×10分割像面处理后当前视场内剩余恒星的分布图;
图27按照9×9分割像面处理后当前视场内剩余恒星的分布图;
图28按照8×8分割像面处理后当前视场内剩余恒星的分布图;
图29按照7×7分割像面处理后当前视场内剩余恒星的分布图;
图30按照6×6分割像面处理后当前视场内剩余恒星的分布图;
图31当前视场内导航星的分布图;
图32是当极限星等为5.2等时,星过滤后、筛选前导航星的分布图;
图33是当极限星等为5.2等和视场为21.91°×16.47°时,运用本发明筛选后的导航星在天球上的分布图;
图34是当极限星等为5.2等和视场为21.91°×16.47°时,筛选前视场中导航星星数的概率分布图;
图35是当极限星等为5.2等和视场为21.91°×16.47°时,筛选后视场中导航星星数的概率分布图;
图36是当极限星等为5.2等和视场为21.91°×16.47°时筛选前和筛选后视场中导航星星数的累积概率分布图。
具体实施方式
下面结合附图及实施例对本发明进行详细说明:
实施例1
星像高密度区有两个特点,一是相等面积内存在星像数多,二是星像之间的距离近。本发明根据这两个特点设计出用于星敏感器的筛选导航星的方法。
首先,按照第一个特点,沿像面探测器的焦平面行、列方向将像面分割成多个等面积的矩形区域,形成一个正交网格。为简化叙述,每个矩形区域称为一个小区(即所述正交网格中的每个网格为一个小区),行、列方向的等分间隔称为尺度。选择某个尺度对像面(也称像平面)进行分割,再实际操作中,采用设定对像面分割的行数为p、列数为q来实现;若星像高密度区含有多颗星,根据较亮的星被探测到的概率大、星像信噪比高的特点,故保留其中最亮的一颗星,通过这种方法处理所有小区。
然后,按照第二个特点,那些距离较近的剩余星必定处于彼此邻域内,也即它们所在的小区是连通的,组成一个连通域,星密度越高,连通域范围越大。若删除最接近最大连通域的质心的星,则可使连通域分裂成多个小连通域,此区域的星密度下降。然后再从处理结果中挑选下一个最大连通域,按照类似方法再处理,直到不再有连通域。
利用该尺度无法再决定到底还可以删除哪颗星,则增大等分间隔,减小等分数,即p和q的取值都减1。
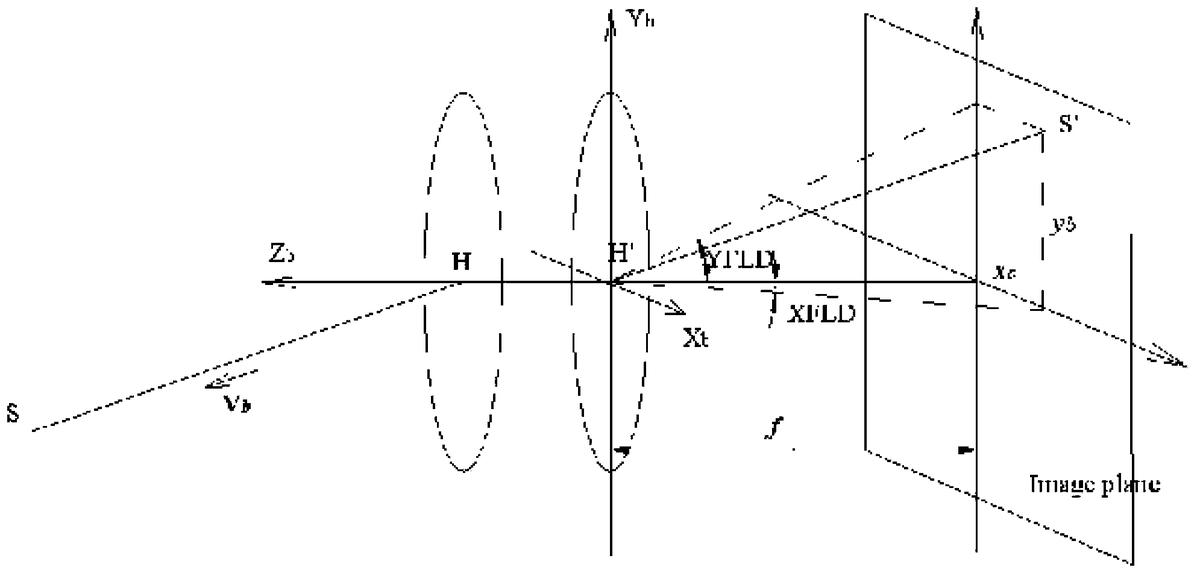
为方便说明本发明的原理,现假设星敏感器本体坐标系建立在光学系统之上,如图1所示。令光学系统等效为理想成像系统,H和H′分别为其物、像方主点,f为光学系统的焦距,星敏感器本体坐标系的原点在像方主点H′处,Xb轴、Yb轴在像方主面内,分别平行于像面探测器焦平面的行和列,Zb轴沿光轴,其正向如图1所示,三轴构成右旋坐标系。恒星S在该坐标系中的方向余弦矢量为Vb,在Xb,Yb方向上的视场角XFLD、YFLD,在像面上的坐标为(xb、yb)。
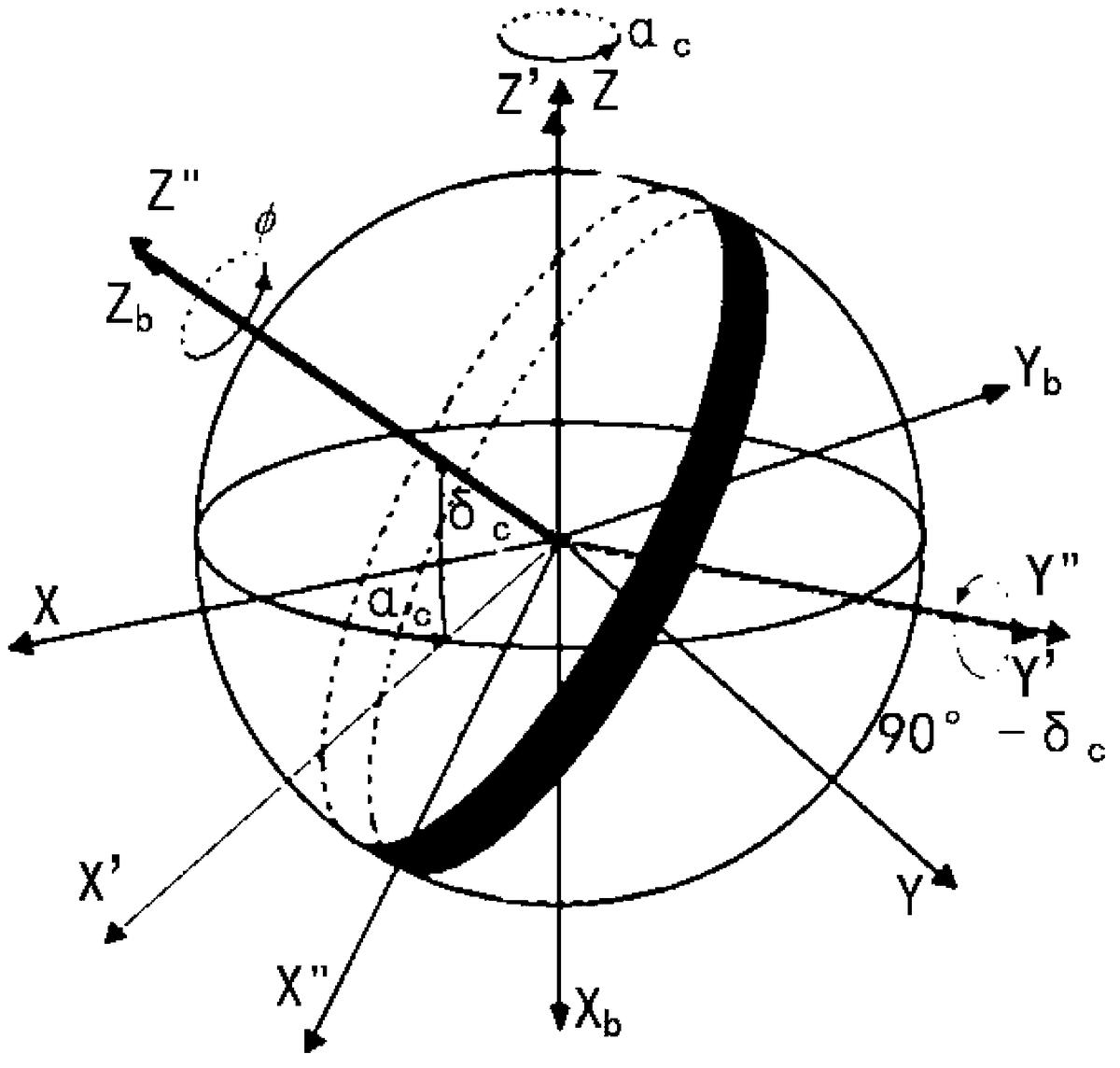
设在惯性坐标系中,光轴指向(αc、δc),可按一定方式旋转惯性坐标系得到本体坐标系。如图2所示,惯性坐标系先绕Z轴由+X轴向+Y轴旋转αc,得到X′Y′Z′坐标系,新坐标系再绕Y′轴由+Z′轴向+X′轴旋转90°-δc,得到X″Y″Z″坐标系,该坐标系绕Z″轴旋转φ,得到本体坐标系XbYbZb。
根据上述星敏感器设定和惯性坐标与本体坐标的转换,本发明所述的采用十字链表的星敏感器筛选导航星的方法,包括:
步骤一、根据星敏感器的极限星等,对全天球的原始星表作星过滤处理,即删除双星、变星和星等高于极限星等的恒星;并根据星图识别算法确定星数阈值Nth;
步骤二、所述星敏感器在当前天区视场内的剩余星的数量设为N,若N≤Nth,则所述剩余星都选为导航星,执行步骤三;
若N>Nth,则通过多尺度像面分割筛选所述当前天区视场内的导航星,其步骤如下:
步骤(1)将所述剩余星成像到像面,把该像面分割为行数为p、列数为q的正交网格;所述正交网格中的每个网格为一个小区;
步骤(2)依次遍历各小区,检查其中剩余星的数量,其中,若一小区剩余星的数量有多颗,则保留其中最亮的一颗星,删除其余星;同时判断此时剩余星的数量,若N≤Nth,则设当前剩余星为导航星,遍历结束,执行步骤三;若N>Nth,则继续遍历;若遍历所有小区后,N仍大于Nth,则把小区当作像元,若小区内有星,则该像元的灰度值为非0,若小区内无星,则该像元的灰度值为0,遍历后的具有剩余星的相邻小区划分为连通域,将正交网格数据存储为十字链表,采用区域增长算法计算出各连通域的质心坐标;
步骤(3)选取小区数最多的连通域,设在该连通域中离该连通域的质心坐标最近的一颗星为冗余星;若该连通域中离质心坐标最近的星有多颗,则其中最暗的一颗星为冗余星;若小区数最多的连通域有多个,则选择这些连通域中最暗的一颗星为冗余星;删除所述冗余星;判断此时剩余星的数量,若N≤Nth,则设当前剩余星为导航星,执行步骤三;若N>Nth,则重复该步骤(3);
步骤(4)若不再有连通域后;N仍大于Nth,则所述p和q的取值都减1,重复步骤(1)至(4);直到N≤Nth;
步骤三、所述当前天区视场的导航星筛选结束后,所述星敏感器转到下一方位重复步骤二筛选导航星,直至遍历全天球。
所述步骤(2)中所述若一小区剩余星的数量有多颗,则保留其中最亮的一颗星,删除其余星的方法包括:
在所述正交网格中预先定义三个二维数组Marray、Idarray和MAGarray;若所述正交网格中第m行、n列的小区有至少有一颗星,则Marray[m][n]=1,否则为零;若所述小区内有多颗星,则用IDarray[m][n]和MAGarray[m[n]分别记录最亮的一颗星的星号和星等,并删除其余星。
所述步骤(2)中所述将正交网格数据存储为十字链表,采用区域增长算法计算出各连通域的质心坐标的方法包括:
步骤A、所述若小区内有星,则该像元的灰度值为非0,若小区内无星,则该像元的灰度值为0,即把所述二维数组Marray转换成一星图,所述各连通域转换成各星象,并将所述星图转换为十字链表;提取灰度值为非0的星图像元的坐标(x,y)和灰度值f(x,y),并把所述星像像元的坐标(x,y)和灰度值f(x,y)存储到十字链表的节点中。
十字链表是一种稀疏矩阵数据结构,各个非0元素通过指针相互串接,成为链表的各节点,每个节点除行、列坐标、元素值外,还以行向量指针right指向同行下一个节点,以列向量指针down指向同列下一个节点。其结构定义为
struct CrossNode{int row,col;TYPE value;
CrossNode*right,*down;}
整个矩阵结构为
struct CLMatrix{int m,n,t;
CrossNode*rv[MaxRows+1];
CrossNode*cv[MaxRows+1];}
其中rv和cv分别代表每行、每列第一个像元的节点,MaxRows表示行数可取的最大值。由以上定义可见,每个节点本身是一个指针,包含链表中的后继数据,其是一种十分紧凑的数据存储结构。
步骤B、定义初始值为0的三个变量ACC1、ACC2、ACC3作为三个累加器。
步骤C、在星图中,一个星像占据一个连通的区域,将该连通的区域称为一个星像区域;以区域增长算法连通一星像区域,即以所述十字链表中的第一个节点为启始种子,依次提取代表邻域节点的像元的坐标(x,y)和灰度值f(x,y),同时将所述的三个累加器分别增加xf(x,y)、yf(x,y)、f(x,y),并将提取过所述坐标(x,y)和灰度值f(x,y)的节点从所述十字链表中删除;重复该步骤三,直至所述星像区域已经连通。
步骤D、使用所述三个累加器计算该星像的质心坐标(xc,yc),即
质心坐标(xc,yc)为: x c = ACC 1 ACC 3 , ]]> y c = ACC 2 ACC 3 . ]]>
步骤E、将所述的三个累加器置0,重复上述步骤C至D,直至所述十字链表为空,即所有星像的质心坐标计算完毕,也就是各连通域的质心坐标计算完毕。
所述p和q的初始值的比值与所述像面的行、列尺寸比相同。
实施例2
在实施例1的基础上实现所述用于星敏感器的筛选导航星的方法,其具体实施过程如下:
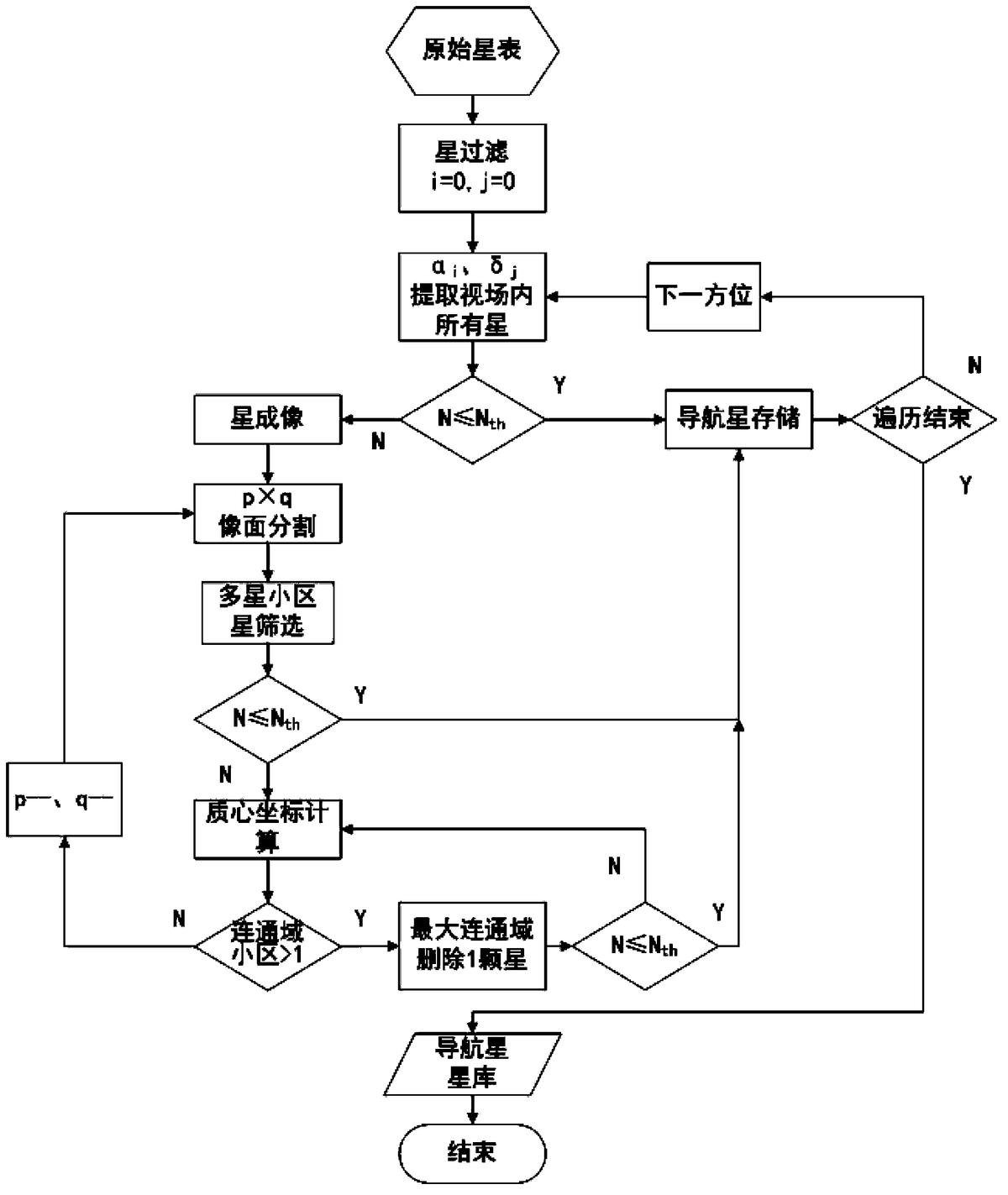
第一步,对原始星表作星过滤处理。根据极限星等删除暗星,同时删除变星、双星,为方便后续处理,剩余星数据按照赤纬以由小到大的顺序排列,并根据星图识别算法确定星数阈值Nth,即根据实际需要选择相应的星图识别算法来确定星数阈值Nth,也可以根据需要自己来设定。
第二步,星敏感器光轴指向全天球上坐标(αi,δi)的位置,αi或δi每次改变1°,遍历全天球。提取每个指向视场内的剩余星,计算剩余星总数N。如果N≤Nth,则所述剩余星都选为导航星;星敏感器光轴转到下一方位,再判断,直到星数大于阈值,开始以下步骤。
提取视场内的剩余星的方法是,首先挑选出坐标(α,δ)满足
|δ-δc|≤wm
的星,其中wm表示星敏感器像面探测器对角线对应的视场角。
上式限定当前视场内剩余星赤纬的上限和下限。由于赤纬δ取值范围是-90°-90°,当δi-wm小于-90°时,应当设置下限为-90°,类似地,当δi-wm大于90°时,上限应设置为90°,得到
剩余星数据按赤纬排序,用两分法确定赤纬值刚好大于δbot星的位置,然后读取后继数据,提取剩余星,直到赤纬值大于δtop。
接着,计算已经提取出的剩余星在本体坐标系中的方位,对于赤经和赤纬为(α,δ)的星,有
V bx V by V bz = cos φ sin φ 0 - sin φ cos φ 0 0 0 1 cos ( 90 - δ i ) 0 - sin ( 90 - δ i ) 0 1 0 sin ( 90 - δ i ) 0 cos ( 90 - δ i ) × ]]>
cos α i sin α i 0 - sin α i cos α i 0 0 0 1 cos α cos δ sin α cos δ sin δ ]]>
它在Xb,Yb方向上的视场角XFLD、YFLD为
XFLD = - t g - 1 ( V bx V bz ) , YFLD = - t g - 1 ( V by V bz ) ]]>
若设光学系统在Xb,Yb方向上的最大视场角为WA和WB。,只有满足
|XFLD|≤WA/2、|YFLD|≤WB/2
的恒星才能被观测到。通过上式筛选得到当前视场中的剩余星,同时也得到它们的视场角XFLD、YFLD,以及它们的总数N。
第三步,将视场内的所有星成像到像面,按
xb=ftan(XFLD),yb=ftan(YFLD)
计算并记录每个星像的位置。
第四步,沿焦平面行、列方向,分割像面为p×q的网格,建立并初始化与网格对应的三个p行q列的二维数组Marray、Idarray和MAGarray,p和q的比值应尽量和焦平面行、列方向尺寸比一致,以保证两个方向的尺度相同。开始时,p和q应取略大的值,以便详细考查星分布密度。数组Marray和Idarray初始化为0,MAGarray初始化为-99.99。
第五步,遍历各小区以计算所提取的星所在的小区。对于坐标为(xb、yb)的星像,它处于像面上第m行、n列的小区有星像,那么
n = floor ( p 2 f tan ( W A 2 ) x b + p 2 - 1 ) ]]>
m = floor ( q 2 f tan ( w B 2 ) y b + q 2 - 1 ) ]]>
其中floor(x)表示取比x小的最近一个整数,Marray[m][n]=1。如果该小区有多颗星的星像,只保留最亮星,IDarray[m][n]记录保留下来的恒星星号,MAGarray[m][n]记录它的星等,更新当前视场内剩余星总数N,即多星小区的星筛选。
第六步,如果N≤Nth,返回第二步,否则进一步作筛选。把遍历后的具有剩余星的相邻小区划分为连通域,其中,小区当作像元,以计算出各连通域的质心坐标,其步骤包括:
步骤a,若小区内有星,则该像元的灰度值为非0,若小区内无星,则该像元的灰度值为0,即把所述二维数组Marray转换成一星图,所述各连通域转换成各星象,并将所述星图转换为十字链表;提取灰度值为非0的星图像元的坐标(x,y)和灰度值f(x,y),并把所述星像像元的坐标(x,y)和灰度值f(x,y)存储到十字链表的节点中;
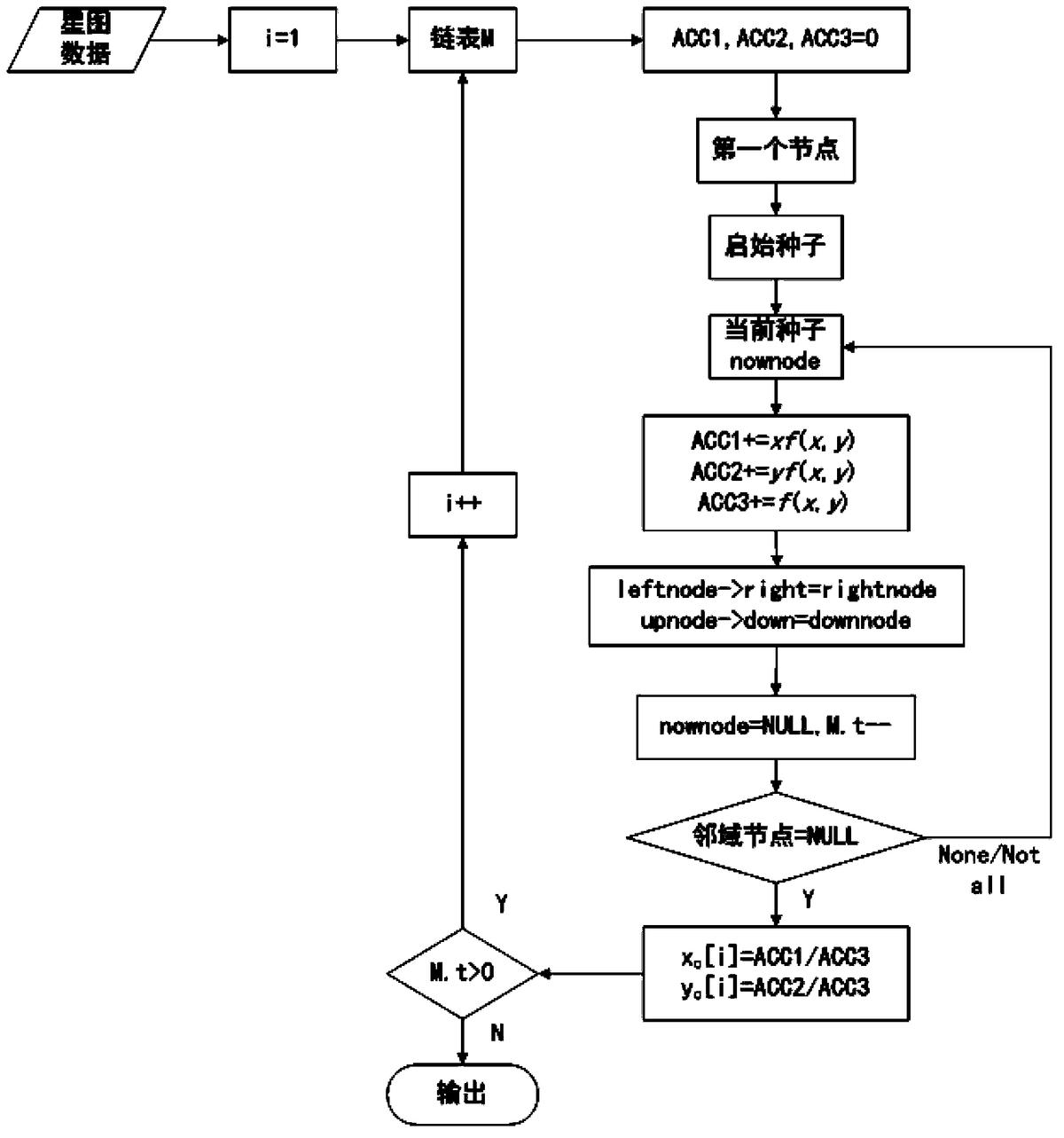
步骤b,定义三个变量ACC1、ACC2、ACC3作为累加器,并初始化为0。以十字链表第一个节点为启始种子。
步骤c,提取当前种子的坐标(x,y)、灰度值f(x,y),累加器ACC1、ACC2、ACC3分别增加xf(x,y)、yf(x,y)、f(x,y)。根据当前种子的行向量指针right,列向量指针down,提取右方、下方最邻近像元,记作rightnode、downnode。由行号row、列号col计算左边、上边最邻近像元,记作leftnode、upnode。将leftnode的行向量指针right指向rightnode,upnode的列向量指针down指向downnode,从而将当前种子从链表中删除,节点总数t减小1。
步骤d,区域增长算法连通一星像区域,当考查四邻域时,只需计算upnode、downnode、leftnode、rightnode。当考查八邻域时,再计算左上、左下、右上、右下四个对角最邻近像元lupnode、ldownnode、rightupnode、rightdownnode。检查这些像元是否处于当前种子邻域内,如果是,则以它们为新的种子。以新种子为当前种子,转向步骤c。否则,同一星像区域全部连通。根据累加器ACC1、ACC2、ACC3的值,计算该星像的质心坐标(xc,yc),即得到所述连通域的质心坐标(xc,yc),。
x c = ACC 1 ACC 3 , ]]> y c = ACC 2 ACC 3 ]]>
步骤e,返回步骤b,直到节点总数t=0,链表为空。
上述步骤a至步骤e简化成流程图,如图3所述。
根据上述步骤a至步骤e计算出每个连通域的质心坐标。选取小区数最多的那个连通域,删除离质心坐标最近的星。如果多颗星离质心坐标都最近,删除其中最暗的星。如果小区数最多的连通域有多个,则删除这些连通域中最暗的星。同时,更新N、Marray,以及IDarray、MAGarray的值。如果N>Nth,重复该步骤,再寻找范围下一个最大的连通域。当N≤Nth时,当前视场内的导航星筛选完毕。如果N>Nth,且任意两颗星所在的小区都不再连通(即无连通域),则执行下一步。
第七步,p和q都减小1,增大均分尺度,像面的小区面积有少量增加,距离较远的几个星像可能又会连通,再从第四步开始执行,直到N≤Nth。
第八步,当全天球遍历完毕,导航星筛选结束。
上述第一步至第八步简化成流程图,如图4所示。
实施例3
在实施例1和实施例2的基础上,对本发明的实施效果作进一步说明。
该实施例以SAO星表作为原始星表;SAO星表(The SmithsonianAstrophysical Observatory Star Catalog/史密松天体物理台星表)是一个天体测量星表,在1966年由史密松天体物理台出版,共包含258,997颗恒星。该星表由之前的一些星表编纂而成,但仅收录9.0等以上且已经精确测量过自行的恒星。SAO星表里的星名由字母SAO开头接着数字序号表示,恒星以赤纬分区,每10度为一区,共分为18区,在每一区中的恒星依照赤经位置来排序。
选取所述SAO星表为原始星表,极限星等为5.5等、视场角为20°×20°,对原始星表星过滤处理后,某光轴指向视场内的剩余星在像面上的星像分布如图5所示,此时共有18颗剩余星,这些星分布不够均匀。
实施方式一
取阈值Nth=7,p和q初始值都取为5,像面按5×5分割后,如图6所示,有多个小区中存在多颗星,各小区删除暗星、保留最亮星后,得到图7,剩余10颗星。图7中,第1到5行,第1、2列,其中有五个小区组成一个连通域,包含星像数最多,该区域星密度高。删除最接近该连通域质心的星,此区域的星密度下降。这五颗星的坐标为(1,1)、(2,1)、(3,2)、(4,1)、(5,1),它们的质心为(3,1.25),它到(3,2)的距离最近,那么删除(3,2)的那颗星,得到图8。此时,共有3个连通域都含有2个小区,它们的连通域范围最大。其中第2行第1列的星最暗,则删除它。剩余的2个连通域含有2个小区,范围最大,第1行第3列的星是这2个连通域中最暗的星,再删除它。这样剩余星数不大于阈值Nth,筛选结果得到如图9和图10所示。
实施方式二
仍对如图5对应的视场内的剩余星筛选,Nth仍取为7,p和q初始值都取为8,像面按8×8分割后,如图11所示,有多个小区中存在多颗星,各小区删除暗星、保留最亮星后,得到图12。
如图12中,第1到4行,第1、2列,其中有四个小区组成一个连通域,包含星像数最多,该区域星密度高。删除最接近该连通域的质心的星,此区域的星密度下降。这四颗星的坐标为(1,1)、(2,2)、(3,1)、(4,1),它们的质心为(2.5,1.25),它到(3,1)的距离最近,那么删除(3,1)的那颗星。接着再从处理结果中挑选最大连通域,按照类似方法再处理,直到任意两颗剩余星所在的小区都不再连通。处理图12后的结果如图13所示,在该尺度内剩余星分布得更加均匀。
利用该尺度无法再决定到底还可以删除哪颗星,则增大等分间隔,减小等分数。将像面分割为7×7共49个等面积区域,得到图14,按照上一尺度的方法作类似处理。如图15再增大尺度,将像面分割为6×6处理,得到图16和17,可见剩余星分布已经非常均匀了,这些剩下的星即可作为导航星。
实施方式三
仍对如图5对应的视场内的剩余星筛选,Nth仍取为7,p和q初始值都取为15,像面按15×15分割后,如图18所示。由于分割尺度较小,各小区最多只含有1颗星。最大连通域都只有2个小区,删除这些最大连通域中较暗的星,结果如图19所示,剩余星数仍大于Nth。此时,直到任意两颗剩余星所在的小区都不再连通,增大等分间隔,减小等分数。将像面分割为14×14共196个等面积区域,得到图20,按照上一尺度的方法作类似处理,结果如图21所示。再将像面分割为13×13共169个等面积区域,得到图22所示,处理后如图23所示。
按上述方法,逐渐按12×12、11×11、10×10、9×9、8×8、7×7、6×6分割像面并处理,得到结果分别如图24至30所示,最终结果如图31所示。
实施方式四
为将本发明的采用十字链表的星敏感器筛选导航星的方法与正交网格法和玻尔兹曼熵算法作比较,表1给出当视场分别取11.5°×11.5°、14°×14°,极限星等分别取6和7.5等时,筛选导航星结果的数据比较。正交网格法和玻尔兹曼熵算法的数据分别来源于发表在Proceedings ofICSP'98会议上的论文《A General Method of the automatically selectionof guide star》和2004年刊登在“ELECTRONICS LETTERS”第40卷第2期的论文《Boltzmann entropy-based guide star selection algorithm forstar tracker》。采用本发明,星数阈值Nth取为6,行、列方向等分数p和q初始值都取为8,由此建立的导航星星库玻尔兹曼熵最小,全天球均匀性最好。从局部天球均匀性来看,正交网格法和玻尔兹曼熵算法得到的导航星星数最大值较大,最小值较小,均匀性也略差。
表1 本发明与正交网格法和玻尔兹曼熵算法的比较
为与回归选取算法,星等加权算法和自组织算法比较,当取视场为8°×8°,极限星等取6.5到7.9之间共7个值时,运用本发明筛选导航星后的结果如表2所示。回归选取算法,星等加权算法和自组织算法数据分别来源于2004年郑胜等发表在“宇航学报”第25卷第1期的《一种新的导航星选取算法研究》,2000年李立宏等发表在“光学技术”第26卷第4期的《一种改进的全天自主三角形星图识别算法》,2002年Hye-Young Kim等发表在IEEE on aerospace conference proceeding s会议上的论文《Self-organizing Guide Star Selection Algorithm for Star Trackers:Thinning Method》。
表2表明,本发明能有效减少高密度天区的星数,而对低密度天区星数影响甚微,95%以上天区视场内导航星数在5到12之间。极限星等较低的时候,导航星数目略多一点,主要是此时有些天区视场内星数小于Nth,周围天区即使有冗余星,也不能删除。
当极限星等为6.5和7.3时,回归选取算法在部分天区删除了过多的星,超过10%的天区导航星数小于5,当极限星等大于7.5等时,该算法建立的导航星星库,仍有很多天区视场内星数太多,星数最大值较大。运用星等加权算法和自组织算法筛选导航星,低密度天区的比例较大。随着极限星等增高,运用自组织算法建立的导航星星库,冗余性越来越大。本发明的方法得到的导航星星库的标准偏差最小,分布最均匀,优于星等加权算法、自组织算法和回归算法。
表2 8°×8°视场时导航星筛选对比
实施方式五
取SAO星表为原始星表,极限星等为5.2等,星敏感器探测器长宽比为4:3,视场为21.91°×16.47°,行、列方向等分数p和q的初始值取12和9,选取星数阈值Nth为6。运用本发明建立导航星星库时,共删除了529颗星,保留了1078颗星。图32和图33分别为导航星筛选前和筛选后在天球上的分布,玻尔兹曼熵由原来的0.0119下降为1.3643×10-4,导航星分布更均匀。
通过全天球遍历,统计筛选前和筛选后的导航星星数分布,结果如图34和图35所示。视场内导航星星数最大值由原来的47,降低为18,而最低值为2保持不变,计算得到的星数标准偏差由原来的6.15降低为1.87,平均星数由13.75颗降低为9.37颗,导航星在局部天球上的均匀性得到改善。图36为视场中导航星星数的累积概率分布,当星数小于4时,导航星筛选前后的两曲线重合,视场内出现4颗以上导航星的概率都为99.94%,表明本发明的方法能有效减少星分布高密度天区的星数量,降低导航星特征冗余性。
显然,上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。而这些属于本发明的精神所引伸出的显而易见的变化或变动仍处于本发明的保护范围之中。
价值度评估
技术价值
经济价值
法律价值
0 0 052.0分
0 50 75 100专利价值度是通过科学的评估模
型对专利价值进行量化的结果,
基于专利大数据针对专利总体特
征指标利用计算机自动化技术对
待评估专利进行高效、智能化的
分析,从技术、经济和法律价值
三个层面构建专利价值评估体
系,可以有效提升专利价值评估
的质量和效率。
总评:52.0分
该专利价值中等 (仅供参考)
本专利文献中包含【1 个技术分类】,从一定程度上而言上述指标的数值越大可以反映出所述专利的技术保护及应用范围越广。 【专利权的维持时间6 年】专利权的维持时间越长,其价值对于权利人而言越高。
技术价值 29.0
该指标主要从专利申请的著录信息、法律事件等内容中挖掘其技术价值,专利类型、独立权利要求数量、无效请求次数等内容均可反映出专利的技术性价值。 技术创新是专利申请的核心,若您需要进行技术借鉴或寻找可合作的项目,推荐您重点关注该指标。
部分指标包括:
授权周期(发明)
34 个月独立权利要求数量
0 个从属权利要求数量
0 个说明书页数
13 页实施例个数
0 个发明人数量
3 个被引用次数
0 次引用文献数量
0 个优先权个数
0 个技术分类数量
1 个无效请求次数
0 个分案子案个数
0 个同族专利数
0 个专利获奖情况
无保密专利的解密
否经济价值 7.0
该指标主要指示了专利技术在商品化、产业化及市场化过程中可能带来的预期利益。 专利技术只有转化成生产力才能体现其经济价值,专利技术的许可、转让、质押次数等指标均是其经济价值的表征。 因此,若您希望找到行业内的运用广泛的热点专利技术及侵权诉讼中的涉案专利,推荐您重点关注该指标。
部分指标包括:
申请人数量
2申请人类型
院校许可备案
0 次权利质押
0 次权利转移
0 个海关备案
否法律价值 16.0
该指标主要从专利权的稳定性角度评议其价值。专利权是一种垄断权,但其在法律保护的期间和范围内才有效。 专利权的存续时间、当前的法律状态可反映出其法律价值。故而,若您准备找寻权属稳定且专利权人非常重视的专利技术,推荐您关注该指标。
部分指标包括:
存活期/维持时间
6法律状态
无权-未缴年费


 苏公网安备 32041202001399号
苏公网安备 32041202001399号



 loading...
loading...